先花10分鐘做個預測了解問題的難度,這邊不對變數做任何處裡直接丟模型,之後會慢慢改善
因為周末要休息了,放個沒有意義的模型給沒用過sklearn的參考
預測台積電10天後收盤價,切訓練7測試3
data['10天交易日後收盤價']=data[['收盤價']].shift(-10)
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
offset = int(X.shape[0] * 0.7)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
from sklearn import ensemble
params = {'n_estimators': 300, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Mean squared error: %.2f"
% mean_squared_error(y_test, y_pred))
print("Mean absolute error: %.2f"
% mean_absolute_error(y_test, y_pred))
Mean squared error: 625.77
Mean absolute error: 22.63
test_score = np.zeros((params['n_estimators'],), dtype=np.float64)
for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, clf.train_score_, 'b-', label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, test_score, 'r-',label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
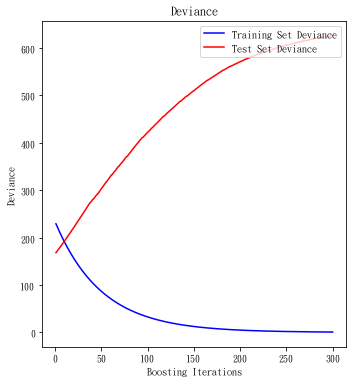
很慘
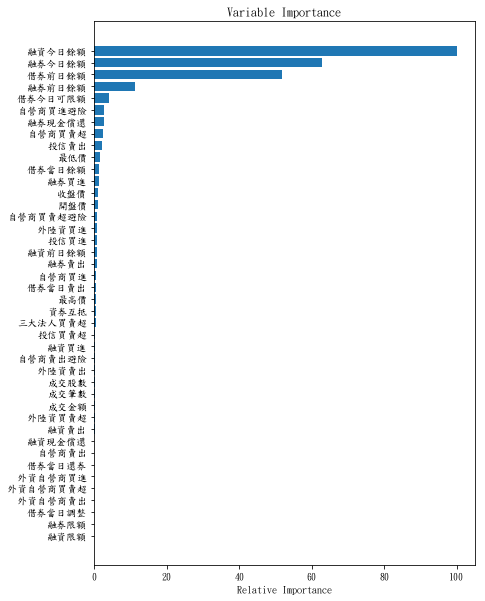
feature_importance = clf.feature_importances_
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, X.columns[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()
data['預測價']=clf.predict(X)
data[['10天交易日後收盤價','預測價']].plot()
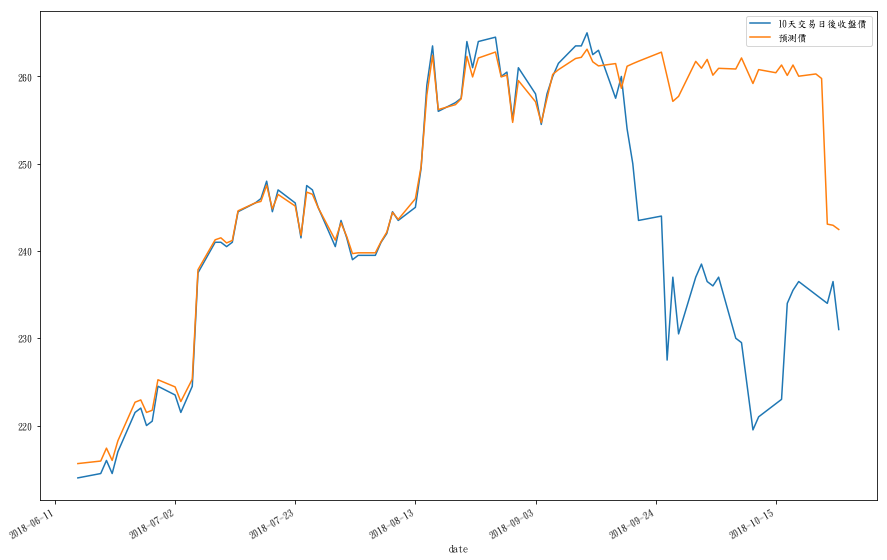
後面3成資料果然預測的很慘

